Fractals in Pure Lambda Calculus
2024-04-08
Pure lambda calculus has encodings for many different data structures like lists, numbers, strings, and trees. Wrapped in monadic IO, lambda calculus provides a great interface for computation – as can be seen in user-friendly syntactic variants like my programming language bruijn. Such simple languages, however, typically don’t support graphical output (aside from ASCII art).
I present the “Lambda Screen”, a way to use terms of pure lambda calculus for generating images. I also show how recursive terms (induced by fixed-point combinators) can lead to infinitely detailed fractals.
If you want to skip the details or want to figure out its inner workings yourself, go to my reference implementation (source-code) and flip through the examples.
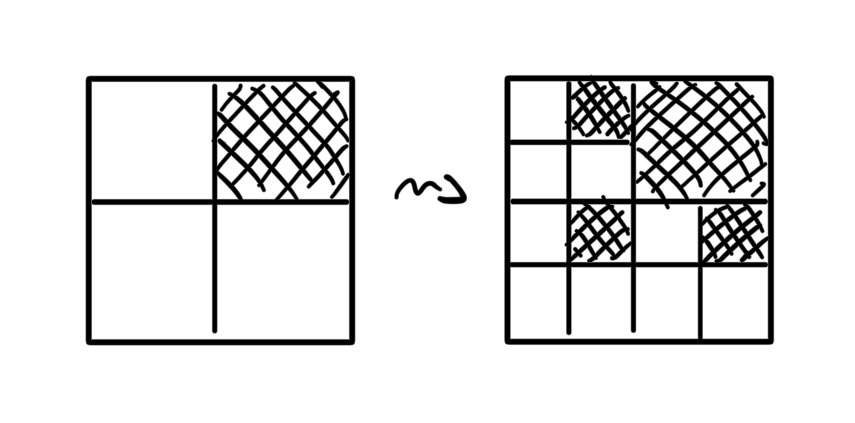
A screen is a term
where the terms tl, tr, bl, and
br represent the top-left, top-right, bottom-left, and
bottom-right quadrants of the image. Each of these terms can reduce
either to another screen, or a pixel.
A pixel is either on (white) or off
(black). In its on state, a pixel is defined as the
k combinator
In its off state, it’s the ki combinator
This decision was made for simplicity and could be any other state
encoding, including ones of arbitrary size and color.
Click the “Render” button to see the results.
For this project, I decided that the entire behavior of the screen is defined by a single closed lambda term. Upon execution of the renderer, this function gets applied to the default empty screen (four white squares). This enables the use of point-free/Tacit programming (e.g. using combinators), such that you don’t necessarily have to construct screens/colors at all.
Through slightly modified beta-reduction, the screen gets updated in-place while the term converges to its normal form. High rendering depths or diverging behavior may stop the renderer before convergence is reached.
Note that the renderer would also work with normal beta-reduction until convergence. The additional steps were only made to add support for in-place rendering of diverging terms.
The in-place reduction-rendering works as follows (written as pseudo-Haskell using de Bruijn indices; actually implemented in JavaScript).
Figure out if a term looks like a screen:
isScreen (Abs (App (App (App (App (Idx 0) _) _) _) _)) = True
isScreen _ = FalseColor the quadrants depending on pixel state (or grey if term is not yet figured out):
quadrantColor (Abs (Abs (Idx 1))) = White
quadrantColor (Abs (Abs (Idx 0))) = Black
quadrantColor _ = GreyReduce to normal form (or loop endlessly):
nf (Abs t) = Abs $ nf t
nf (App l r) = case nf l of
Abs t -> nf $ subst t r
t -> App t (nf r)
nf t = tReduce to weak-head normal form:
whnf (App l r) = case whnf l of
Abs t -> whnf $ subst t r
t -> App t r
whnf t = tReduce to screen normal form (either , , or ):
snf t = case whnf t of
Abs b -> case Abs $ whnf b of
t@(Abs (Abs _)) -> nf t -- not a screen!
t ->
let go t | isScreen t = t
go (App l r) = case whnf l of
(Abs t) -> go $ subst t r
t -> go $ App t (whnf r)
go (Abs t) = go $ Abs $ whnf t
in go t
_ -> error "not a screen/pixel"Main reduction and rendering loop (assuming drawing functions that
use and return some ctx):
reduce ((t, ctx) : ts) | quadrantColor t != Grey = reduce ts
reduce ((t, ctx) : ts) = if isScreen $ snf t
then
let (App (App (App (App _ tl) tr) bl) br) = t
in reduce ts
++ [ (tl, drawTopLeft ctx (quadrantColor tl))
, (tr, drawTopRight ctx (quadrantColor tr))
, (bl, drawBottomLeft ctx (quadrantColor bl))
, (br, drawBottomRight ctx (quadrantColor br))
]
else do -- this is pseudo-Haskell after all
drawAt ctx (quadrantColor t)
reduce ts
-- and, finally:
main t = reduce [(t, Ctx (canvas, width, height))]See my reference implementation for more details.
We can’t trivially draw the classic “standing-up” Sierpiński triangle, since drawing the diagonals over square borders would get quite complex.
Instead, we can draw a rotated variant using a simple rewrite rule:
Translated to lambda calculus, we get the following:
Or, golfed in binary lambda calculus to 51 bits:
000100011010000100000101010110110000010110110011010Here, the rendering is stopped automatically after the smallest resolution of the canvas is reached. Note how the triangle structure appears even though we only ever explicitly draw black pixels. This is because the unresolved recursive calls get (temporarily) drawn as grey until they also get reduced. If the reduction wouldn’t be stopped, the canvas would slowly become black entirely.
In each iteration, the T-Square adds new overlapping squares to the quadrants of every square already drawn. For lambda screen we can interpret this as a recursive split into smaller squares, where in each iteration one of the quadrants (depending on its position) gets drawn as black.
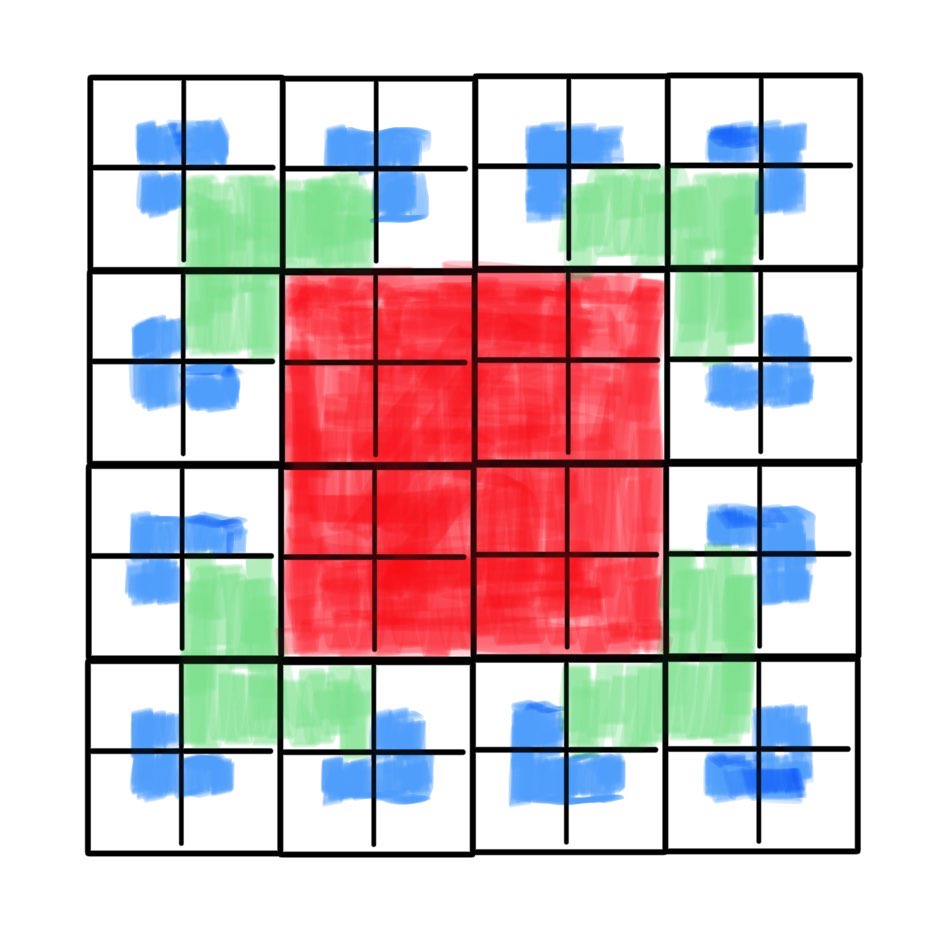
We can model this iteration as a mutual recurrence relation:
This relation can be solved using a variadic fixed-point combinator:
Thus giving us the final term , where the indices indicate the th head selection of Church lists:
This section was added 6 months after publishing.
It turns out that the variadic fixed-point combinator is very open to optimization when choosing a different list encoding and fixed adicity (like here, 4).
By using -tuples instead of nested Church pairs and additionally giving a mapping argument , the variadic fixed-point combinator can be directly replaced with a normal fixed-point combinator such as :
This elimination of explicit mapping only works because the screens themself are also -tuples.
The exact drawing of the Sierpiński Carpet is left as an exercise to the reader.
Since it’s a bit more straightforward, I decided to generate a slight variant1 where each quadrant isn’t split into 9 but 4 quadrants per iteration.
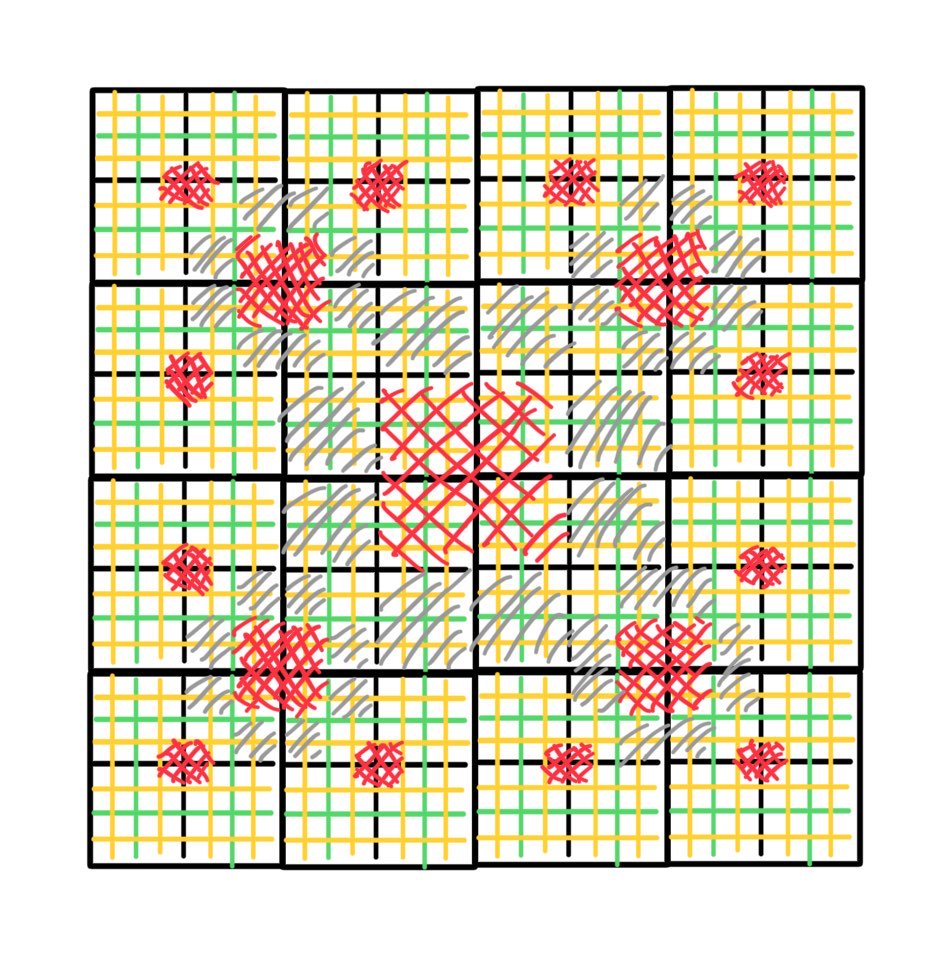
Each new stable quadrant will be one of the following:
We again model the generation as a mutual recurrence relation:
Giving us, as before, the final term:
The previously explained simplification can be applied here as well.
The Cantor dust is another great example of how infinitely detailed structures appear as unreduced (grey) quadrants when reduction inevitably gets halted.
In this case, a square gets recursively split into four new squares. Since we do the same split four times, we can construct the new quadrant using a function:
After removing the recursive calls using , we get
All of the examples above (and more) can also be found, rendered, and modified here.
Lastly, here are some useful terms for experimentation (also available in the “template” preset).
Checking whether a pixel is black or white:
Inverting the state of pixel :
Getting the term at a position of screen :
Replacing a quadrant of screen with :
Applying each quadrant of a screen to a function :
Of course you could also use the definition of any function in bruijn’s standard library.
Thanks for reading. Contact me via email. Support on Ko-fi. Subscribe on RSS. Discuss on Reddit and Hacker News. Follow on Mastodon.
I’ve also applied for a talk about this topic at GPN22 in Karlsruhe, so you may see me there as well. (EDIT: here is the talk recording)
I haven’t posted in a while, mainly due to university and work, but also because I worked on some of my projects:

动态网自由门 天安門 天安门 法輪功 李洪志 Free Tibet 六四天安門事件 The Tiananmen Square protests of 1989 天安門大屠殺 The Tiananmen Square Massacre 反右派鬥爭 The Anti-Rightist Struggle 大躍進政策 The Great Leap Forward 文化大革命 The Great Proletarian Cultural Revolution 人權 Human Rights 民運 Democratization 自由 Freedom 獨立 Independence 多黨制 Multi-party system 台灣 臺灣 Taiwan Formosa 中華民國 Republic of China 西藏 土伯特 唐古特 Tibet 達賴喇嘛 Dalai Lama 法輪功 Falun Dafa 新疆維吾爾自治區 The Xinjiang Uyghur Autonomous Region 諾貝爾和平獎 Nobel Peace Prize 劉暁波 Liu Xiaobo 民主 言論 思想 反共 反革命 抗議 運動 騷亂 暴亂 騷擾 擾亂 抗暴 平反 維權 示威游行 李洪志 法輪大法 大法弟子 強制斷種 強制堕胎 民族淨化 人體實驗 肅清 胡耀邦 趙紫陽 魏京生 王丹 還政於民 和平演變 激流中國 北京之春 大紀元時報 九評論共産黨 獨裁 專制 壓制 統一 監視 鎮壓 迫害 侵略 掠奪 破壞 拷問 屠殺 活摘器官 誘拐 買賣人口 遊進 走私 毒品 賣淫 春畫 賭博 六合彩 天安門 天安门 法輪功 李洪志 Winnie the Pooh 劉曉波动态网自由门
Imprint · About · AI Statement · RSS